Applications that can process natural language are very much in vogue right now. Conversational agents like text-processing chatbots and speech-processing virtual assistants have long since become an indispensable part of everyday life for many people: as practical personal helpers but also in the area of customer service and in-house information processing.The number of conversational agents (CA) is growing rapidly, and with it the expectations the industry and users have towards this technology: CAs are not only required to provide information correctly and instantaneously, the interaction itself should also be as intuitive and human-like as possible. While the former is achievable through a sound framework and good programming, the latter can only be achieved by training conversational agents extensively – a task that is larger than many people think.
The importance of natural language processing (NLP)
The heart, or rather the mind of conversational agents is their ability to process natural language. During the early years of its development, natural language processing was very limited and for many years that followed, language-based human-computer interaction had to rely on rules and decision trees. The resulting interactions were thus often still far from natural-feeling conversation.
This changed with the advancements that were made in machine learning in recent years, which also resulted in quite an advancement in natural language processing. While early attempts at chatbots, like MIT’s ELIZA, were not able to identify the intent of language inputs, neural networks and deep learning have given modern chatbots and virtual assistants; the ability to recognize the intention behind user input. This means the conversational agent can follow relatively free text inputs and react to them even though they are not necessarily linear.
Rule-based vs. free-text CAs
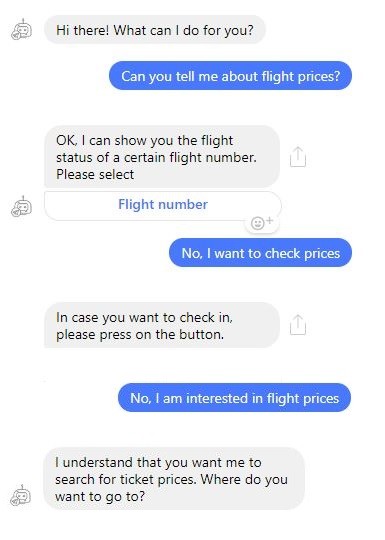
Imagine a chatbot that is developed to take pizza orders from customers. Such a bot will still often be rule-based and function as a slightly advanced order form, where each piece of information must be put into a specific field for the order to be completed. In this scenario, the bot is in complete control of the interaction with the customer, because it determines what information (entity) is given when: The chatbot asks for a specific entity, for example what pizza or toppings the customer would like, and the customer provides the information in the order the bot requests, either by natural language inputs or by selecting the answer from a given list. While very efficient and reliable in its designated task, the ordering process with a rule-based CA does not feel like a conversation with a real human.
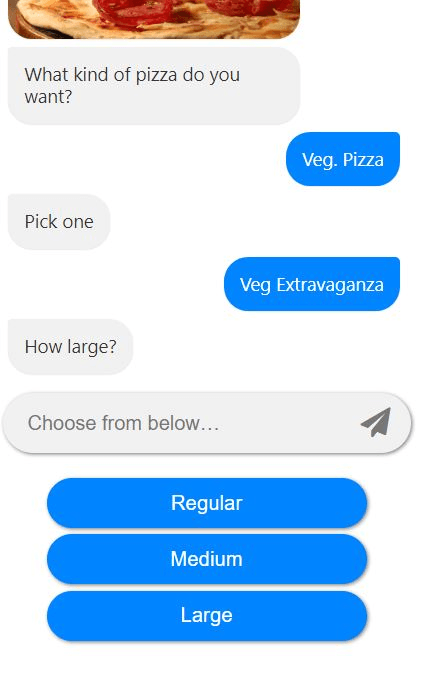
A pizza chatbot that is connected to a natural language understanding platform could conduct the ordering process in a more human-like way. With the ability to identify the intent behind a language input, the bot would potentially be able to run through the same conversation with an infinite number of input variations. So, instead of waiting for the bot to ask for a specific entity and then selecting it from a pre-defined list, a customer could simply write “Hi, I’d like a medium veg pizza, extra cheese, and a diet coke.” The bot in this scenario would be able to identify and differentiate between the entities it has received (“medium”, “veg pizza”, “extra cheese”, “diet coke”) and the intent of the customer (to order a pizza and a drink).
For ordering processes, rule-based conversational agents usually offer a sufficiently good user experience, because customers are used to the fact that ordering processes are linear, and that they are required to input certain information at specific points. However, in many other situations where conversational agents are employed, a solely rule-based approach won’t work. This is especially true for virtual assistants like Siri or more advanced customer service chatbots, because conversations with such CAs can go into a lot of different directions. In those situations, conversational agents must be able to recognize the intent behind a natural language input to react appropriately, which is much harder for machines than it is for humans.
Chatbots need to be tested
As stated by Moravec’s paradox, many tasks that are performed unconsciously and with ease by humans are extremely difficult for computers. For humans, understanding and using language is one of the first things we learn as children. Reading and writing complicated texts or leading complex discussions may still require a lot of thought process and concentration, but most of us do not have to think about basic communication: When we casually talk to or write with people in a shared language, we expect to be understood and often do not even consider that our conversational partner might get lost in the interaction.Conversational agents also have to learn how to use language.
While the ability to identify the intent behind an input gives them the appearance of understanding language, the processing of language does not involve a true understanding of it. This difference between humans, who can use and understand language, and conversional agents, who can use but not understand language, can severely impact the UX of such applications. The more human-like a virtual assistant or chatbot appears, the more the user will treat the CA as human.
On the one hand this effect is desired, because users feel more comfortable with and trusting towards an application that is emulating human behavior. On the other hand, this effect makes the user less tolerant of instances where the CA displays non-human properties, like misunderstanding an input or replying in wrong or unfitting ways. Besides frustrating the user, such instances destroy the illusion of humanness that developers of conversational agents work so hard for. To ensure a good user experience, extensive language training is therefore key.
Using the right language training data
The semantic and syntactic variety of natural language make a broad language training extremely difficult. For example, if we want to know the cost of a specific item, we can ask “what does it cost?”, “how much is it?”, “how much do I have to pay for it?”, “could you tell me the price?”, etc. The CA might directly recognize the terms “cost” and “price” as an intent to learn more about the cost of an item. “pay”, on the other hand, could also signify an intention to start a payment process or learn more about payment options. “How much” is even more abstract and might not be recognized as related to costs at all, if the bot is not specifically trained to consider the expression in this context.
![]()
The examples above are all common phrases for enquiring about the cost of something and it is very probable that developers in charge of training CAs would come up with all four phrases (if they think that users might be asking for a price). However, expressing 15 to 30 different ways of asking for a price might already become difficult for one person, thinking of 50 to 100 variations seems impossible.
And yet there are even more possibilities of phrasing that question, depending for example on how the person asking for the price usually talks.In addition to different language styles, written and spoken dialects as well as mistakes in grammar and spelling are also common in natural language and have to be accounted for. For virtual assistants, another challenge is training the application to recognize a large variety of voices and to differentiate between language inputs and background noises.
The training conversational agents receive during their development often only cover language basics, such as the most common terms and phrases the developer can come up with. This leads to a passable user experience at best. To make a CA appear human-like, and thereby create a good or even outstanding user experience, requires more: real-life training data from as many different users as possible.
Does your bot need someone to talk to?
To make your bot as human as possible, Testbirds provides chatbot & virtual assistant testing for usability and UX, as well as functional testing. Bots need friends too, or at least someone to talk to — contact us now to make sure your bot isn’t lonely!
Testbirds specialises in the testing of software such as apps, websites and Internet of Things applications by using innovative technologies










